defAskurl(url): s = Service(r"E:\python\PyCharm Community Edition 2021.3.1\plugins\python-ce\helpers\typeshed\stubs\selenium\selenium\webdriver\chrome\chromedriver.exe") #这是chromedriver存放位置 driver = webdriver.Chrome(service=s) driver.get(url) driver.switch_to.frame("g_iframe") #锁定子页面 text = driver.page_source return text
from bs4 import BeautifulSoup import re import xlwt from selenium import webdriver from selenium.webdriver.chrome.service import Service import os import requests
defAskurl(url): s = Service(r"E:\python\PyCharm Community Edition 2021.3.1\plugins\python-ce\helpers\typeshed\stubs\selenium\selenium\webdriver\chrome\chromedriver.exe") driver = webdriver.Chrome(service=s) driver.get(url) driver.switch_to.frame("g_iframe") text = driver.page_source return text
html = Askurl(url) soup = BeautifulSoup(html,"html.parser")
for item in soup.find_all('div', class_="ttc"): item = str(item) data1 = [] name = re.findall(FindName, item)[0] name = name.replace('\xa0'," ") data1.append(name)
# for index in Singer: # print(index) # for index in Sing: # print(index)
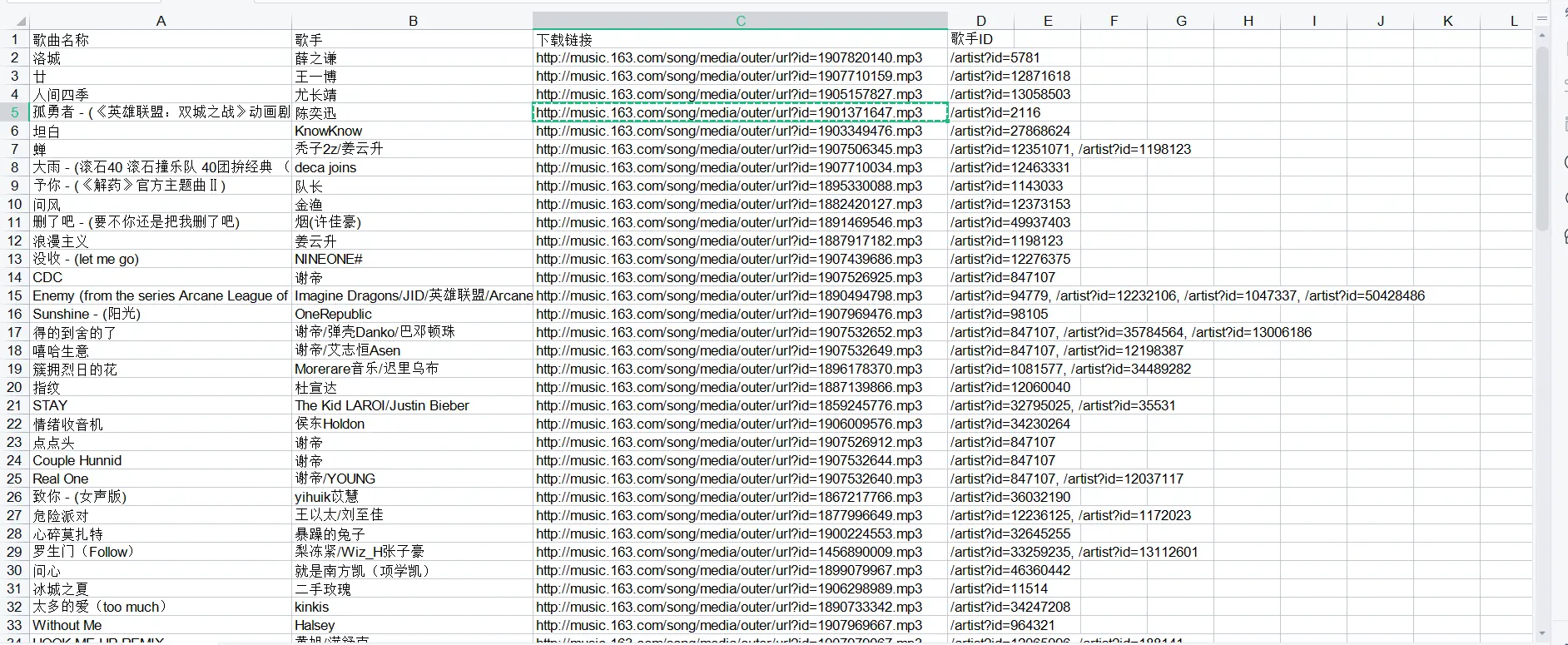
defSavedata(path): work = xlwt.Workbook(encoding="utf-8", style_compression=0) sheet = work.add_sheet("wyyMusic", cell_overwrite_ok=True) col = ('歌曲名称', '歌手', '下载链接', '歌手ID') for i inrange(0, 4): sheet.write(0, i, col[i]) # write前两个数据分别是行和列的坐标 for j inrange(0, len(Sing)): data = Sing[j] sdata = Singer[j] for k inrange(0, 2): if k==0: i=0 else: i=2 sheet.write(j + 1,i, data[k]) for k inrange(0, 2): if k == 0: i = 1 else: i = 3 sheet.write(j + 1, i, sdata[k]) work.save(path) print("save completely")
defdownload(): for i inrange(0,3): #这是要下载的歌曲的排名区段(一到三名) item = Sing[i] url = item[1] # MP3保存文件夹 save ='E:\py下载' name = item[0] + '.mp3' # 文件夹不存在,则创建文件夹 folder = os.path.exists(save) ifnot folder: os.makedirs(save) # 读取MP3资源 res = requests.get(url,stream=True) # 获取文件地址 file_path = os.path.join(save, name) print('开始写入文件:', file_path) # 打开本地文件夹路径file_path,以二进制流方式写入,保存到本地 withopen(file_path, 'wb') as fd: for chunk in res.iter_content(): fd.write(chunk) print(name+' 成功下载!')